
October 29, 2024
OCR (Optical Character Recognition) tools utilize Machine Learning algorithms to extract characters from a digital image or scanned file.
This technology enables many individuals and industries to streamline their workflow by digitizing data for easy access and storage.
Plus, the advanced OCR tools come with batch-processing capabilities. So, they can extract text from multiple images at once. This feature allows companies to create large datasets that they can later utilize to make well-informed decisions.
In this post, we will discuss how OCR helps in extracting text from multiple images at once. We will also learn the way to leverage a tool from the internet to complete day-to-day tasks.
Shape the Future of Tech! Join the Developer Nation Panel to share your insights, drive tech innovation, and win exciting prizes. Sign up, take surveys, and connect with a global community shaping tomorrow’s technology. Join Now
How OCR Works: The Basics
We will start-off by highlighting the basics of OCR and how it works to extract text from multiple images at once.
1. Image processing
Images are cleaned and prepared for the text recognition process. The OCR engine binarizes (converts the image to black and white), reduces the noise, corrects the skew, and then detects the edges of characters so they’re clearly captured.
2. Text Detection
After preprocessing, the OCR engine detects areas of the image that likely contain text. These segregated areas are processed further by detecting a gradient in brightness between the text and the background color. For this step, algorithms such as convolutional neural networks (CNNs) can be used to detect text regions.
3. Character Segmentation
In this step, the OCR engine breaks the detected text regions into individual lines and characters. Connected component analysis is used by some systems and contours by others to find characters.
However, the challenge here is to correctly distinguish between letters that touch each other or are spaced irregularly.
4. Pattern Recognition (Character Recognition)
This is the heart of OCR process and can happen in two primary ways:
Template Matching: Training the algorithms to compare each detected character to a database of known patterns. The engine does its best when the fonts and size does not change, but cannot handle different font or style variations.
Feature Extraction: The approach extracts distinct features of each character (given by lines, curves, and intersections), and applies algorithms such as k nearest neighbors (KNN) or neural networks to recognize the text.
5. Post-Processing
Once the characters are recognized, post-processing corrects errors and improves accuracy. For example, the system can use a dictionary to fix misrecognized words or apply NLP models to predict and fix common OCR mistakes such as reading “rn” as “m.”
Ways OCR Helps Getting Text from Multiple Images
When the OCR technology first started to commercialize, there were a lot of limitations. First, the software and tools were mostly licensed and paid. Secondly, you couldn’t process many images at once; it was one at a time and a very time-consuming process.
From that, we’ve come a long way. The OCR tools that we have today are much faster and more robust than in the past, one of which we will discuss in this article. We will also see how the advanced tech supports batch-processing capabilities while maintaining accuracy.
1. Batch-Processing
Newer OCR tools allow users to upload many image files at once for conversion. This is called batch-processing and it allows companies with big data sizes to quickly digitize their physical documentation.
A tool that we think is necessary to mention here is the Imagetotext.io. It helps users process 50 images at once with lightning-fast speeds and high accuracy.
The OCR tool has a very minimalist user interface, which keeps the learning curve much gentler. To use the tool, we simply dragged and dropped the image files into the interface to receive the following output.
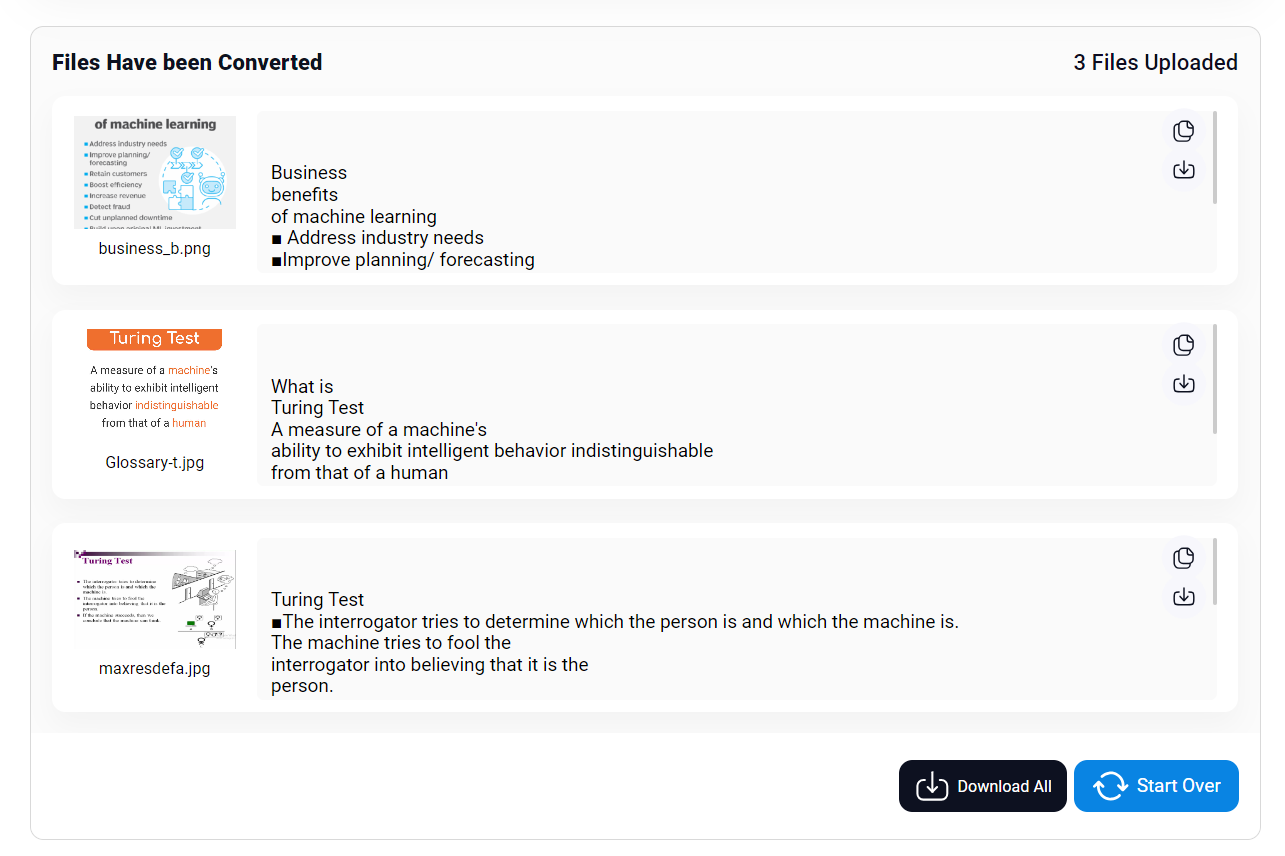
The text was immediately extracted for all the 3 files we uploaded to this OCR tool. If we want to do this for more images, then purchasing the premium package with some additional features might be the way to go.
Thus, explicitly showing how imagetotext.io has accurate batch-processing capabilities for handling a large sample size of documents.
2. Multi-Format Image Support
Not only batch-processing, but the advanced OCR tools (like the one we just mentioned) are also capable of supporting multiple file formats. These include:
- PNG
- JPG
- JPEG
- WEBP
- BMP
- TIFF
- And more …
This support for a vast range of image formats makes OCR technology perfect for different use cases. A person working on freelance projects can directly fetch an image from the internet using its URL to convert it to editable text.
Similarly, an organization with a wide team structure working with complex imagery in TIFF format can get the text in editable form using the tool we discussed. All of these things elevate the functionality of individuals or work teams, immensely boosting their productivity.
3. Maintaining High Accuracy
As we saw in the pictorial demonstration, modern-day OCR tools are capable of maintaining their high accuracy during batch-processing of images.
This feature makes the technology crucial for eliminating errors associated with manual data entry. Thus, making the information that reaches the databases accurate and dependable.
Besides that, a pristine text extraction process ensures that there is no loss of data, making the knowledge bases comprehensive.
However, it is never a bad idea to cross-check the extracted text so that you can avoid the rare slip-ups that these tools can sometimes make.
4. Layout Preservation
ML algorithms have developed so quickly that the OCR tools can now ensure layout preservation of text almost every time. As an example, consider the image below with advanced mathematical text.

Let us put the mentioned OCR tool to test with this image and see if it can retain the layout (mathematical symbols, etc.) in the extraction process.
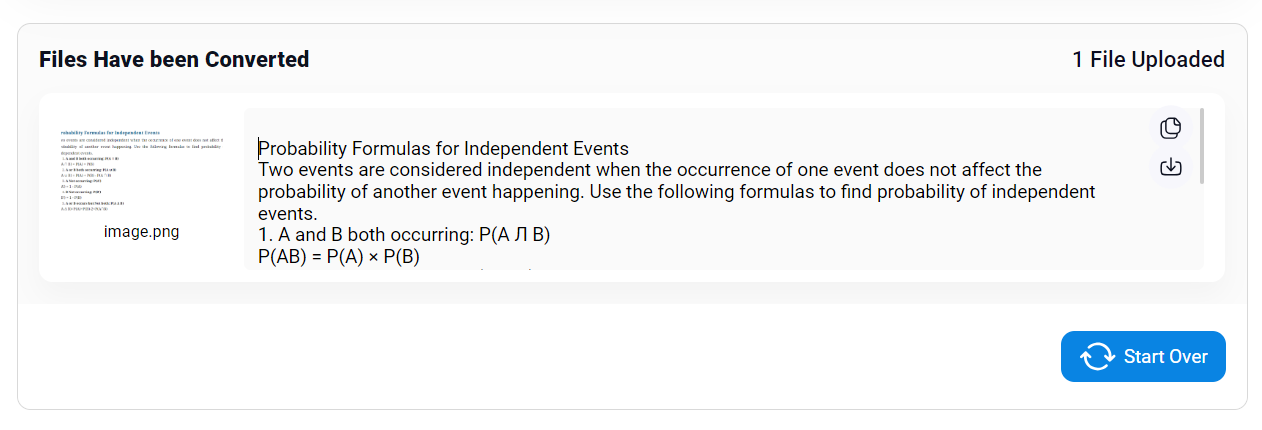
Indeed, achieving such layout preservation levels for OCR tools is a statement that our technology is advancing at a rapid pace. Thus, no matter how many images you put in for the process, there will be no variation in the textual formatting of the extracted data.
5. Integration with Other Tools
Modern OCR tools can integrate with a lot of other useful tools. These may include translators, transcribers, and so on.
Thus, image-to-text conversion isn’t just limited to digitizing information. But, the technology can also be used to make one-stop solutions for users where everything is done accurately and rapidly.
Companies can also leverage OCR to add accessibility features like TTS (Text-to-Speech) to their platforms. This can allow visually impaired individuals to navigate websites conveniently, thus adding inclusivity to the user experience (UX).
There are many more ways OCR helps to extract text and integrates with other applications or APIs. However, we’ve mentioned some of these in this post just to give you an idea of how this technology can help scale up your business.
Technical Details for Developers
For a developer, building or integrating OCR requires understanding some of the following aspects.
1. Image Preprocessing Techniques
- Binarization: Converting gray images to binary makes OCR engines detect text easier, and algorithms such as Otsu’s method or adaptive thresholding are used for that.
- Noise Reduction: Median filtering and morphological operations (like dilation and erosion) are techniques for cleaning the image, that is, removing irrelevant noise.
- Skew Detection and Correction: A popular way to look for skew in scanned images and turn them back into horizontal orientation is to use Hough Transform.
2. Machine Learning and Deep Learning Techniques
Modern OCR systems often use deep learning models like CNNs for recognizing characters, words, and even handwritten text. LSTM (Long Short Term Memory) neural network has been integrated by tools such as Tesseract (an open source OCR engine) to deal better with complex text layouts, resulting in higher recognition accuracy.
3. Handling Different Languages and Scripts
OCR must be adaptable to different languages, fonts, and character sets. Mostly, we train the model on several datasets including mundane English words, English named entities (e.g., @realDonaldTrump), Chinese characters, Japanese characters, Arabic, and other right-to-left languages.
OCR systems can be fine tuned with specific datasets, to increase accuracy. But, this requires enough understanding and working experience with APIs and model training.
4. Accuracy Improvements
To enhance accuracy, OCR systems can be fine-tuned with specific datasets. Training custom models for industry specific fonts or handwriting style is vital for OCR use cases like reading of financial forms, invoices or legal documents.
A lot of developers include OCR by utilizing Google Cloud Vision APIs, AWS Textract or Microsoft Azure Cognitive Services.
5. Real-Time OCR
For mobile or camera-based applications, real-time OCR adds another layer of complexity, requiring efficient algorithms that work on lower-quality images and in varied lighting conditions. Developing applications under such conditions requires developers to optimize for processing times and to cope with lower resolution or motion blur.
Conclusion
OCR tools use machine learning algorithms to extract text from images, enabling individuals and industries to quickly digitize data for easy access.
Advanced OCR tools support batch processing, allowing for the extraction of text from multiple images simultaneously.
This technology maintains high accuracy, preserves layouts, and can integrate with other useful tools, making it a valuable asset for enhancing productivity and accessibility in various big-scale applications.
Recent Posts


August 27, 2025
How to Find the Right Learning Path When You’re Switching to a Tech Career
See post


August 27, 2025
The Hidden Challenges in Software Development Projects: Key Insights from Our Latest Survey
See post


August 22, 2025
Developer News This Week: AI Speed Trap, GitHub Copilot Agents, iOS 26 Beta Updates & More (Aug 22, 2025)
See post